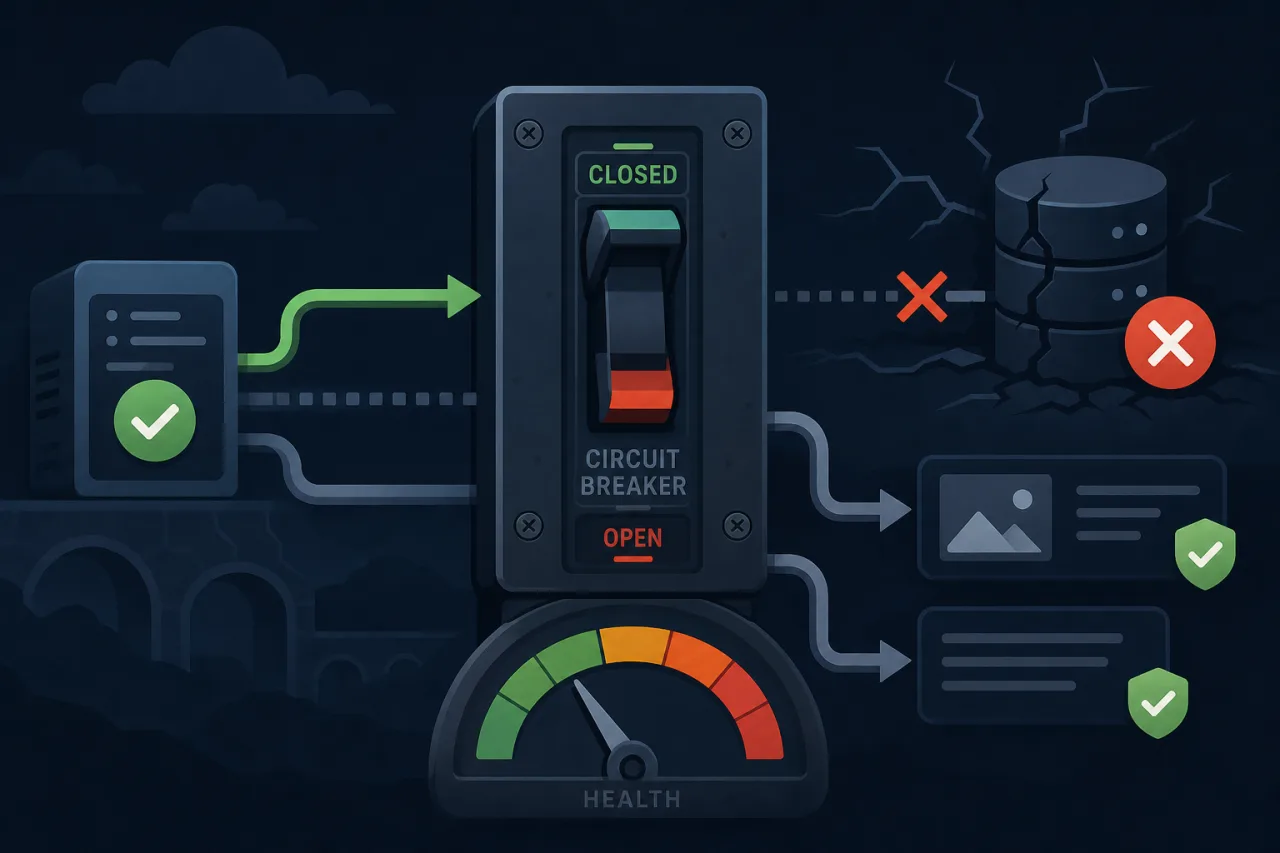
The Problem: Cascading Failures
When one dependency goes down — a payment API, a recommendation service, a database read replica — the naive response is to keep retrying. Threads pile up waiting for timeouts. Connection pools exhaust. What started as a partial outage becomes a full one.
Graceful degradation and the circuit breaker pattern are two complementary tools that prevent this cascade.
Graceful Degradation
Graceful degradation means your system continues to serve a reduced but useful response when a dependency is unavailable, rather than failing completely.
Concrete examples:
- An e-commerce site can't reach its recommendation engine → show bestsellers from a cached list instead of a personalised feed.
- A news site can't reach its comment service → render the article without comments rather than a 500 page.
- A dashboard can't reach a metrics API → display the last successfully cached data with a "data may be stale" notice.
The key decision you need to make for each dependency is: what is the acceptable fallback? Sometimes that's cached data. Sometimes it's a static default. Sometimes it's simply hiding the feature.
Designing for Degradation
- Map your dependencies. List every external call your service makes — databases, third-party APIs, internal microservices.
- Classify each by criticality. Is this dependency on the critical path (request fails without it) or non-critical (request degrades without it)?
- Define the fallback for each non-critical dependency. Write it down. Implement it. Test it by actually killing the dependency in staging.
- Return meaningful signals to callers. Use HTTP headers, response fields, or status endpoints to indicate degraded mode so downstream consumers and monitoring tools know what's happening.
The Circuit Breaker Pattern
Graceful degradation tells you what to return when something is broken. The circuit breaker pattern tells you when to stop calling the broken thing at all.
The pattern comes from electrical engineering. A circuit breaker trips when it detects a fault, stopping current flow to prevent further damage. You reset it once the fault is cleared.
States
A circuit breaker sits in one of three states:
- Closed — requests flow through normally. Failures are counted.
- Open — the failure threshold was exceeded. Requests are immediately rejected (or routed to the fallback) without hitting the dependency. A timer starts.
- Half-open — the timer has expired. A limited number of probe requests are allowed through. If they succeed, the circuit closes. If they fail, it opens again.
Implementing a Circuit Breaker
Here's a minimal conceptual implementation in pseudocode:
if circuit.state == OPEN:
return fallback_response()
try:
response = call_dependency()
circuit.record_success()
return response
except Exception:
circuit.record_failure()
if circuit.failure_count >= THRESHOLD:
circuit.trip() # move to OPEN
return fallback_response()
In practice, use a battle-tested library rather than rolling your own:
- Python:
pybreaker - Java/Kotlin: Resilience4j (also covers retry, bulkhead, rate limiter)
- Go:
gobreaker(sony/gobreaker) - Node.js:
opossum - .NET: Polly
Tuning the Parameters
Three numbers drive circuit breaker behaviour:
| Parameter | What it controls | Starting point |
|---|---|---|
| Failure threshold | How many failures before tripping | 5 failures in 10 seconds |
| Open duration | How long before probing resumes | 30–60 seconds |
| Half-open probe count | How many test requests before closing | 1–3 requests |
These are not universal values. A slow third-party API warrants different thresholds than an internal cache. Set them based on observed p99 latency and acceptable error rates for each dependency.
Where Uptime Monitoring Fits In
Circuit breakers are runtime mechanisms — they react to failures as they happen inside your application. External uptime monitoring gives you the outside-in view: is the dependency actually reachable from the network, and is it reachable from multiple regions?
If Pingy shows a dependency is down from three separate regions simultaneously, you have confirmation that the circuit breaker should stay open and the incident is external, not a bug in your own code. That distinction matters when you're deciding whether to page your on-call engineer or wait for a vendor status update.
Key Takeaways
- Map every external dependency and decide whether it's critical or non-critical before an outage forces the decision.
- Define and test your fallback for every non-critical dependency — a fallback you haven't tested is a fallback that probably doesn't work.
- The circuit breaker pattern stops retry storms by short-circuiting calls to a known-broken dependency.
- Use an established library (Resilience4j, Polly, opossum) rather than reimplementing the state machine yourself.
- Tune thresholds per dependency, not globally.
- External multi-region monitoring gives you the outside-in signal to confirm whether a tripped circuit breaker reflects a real infrastructure problem or a local anomaly.