Tutorials
Practical guides on uptime, monitoring, DRaaS, load balancing and AWS reliability from Pingy.io. Tracking an incident? See Outage Reports.
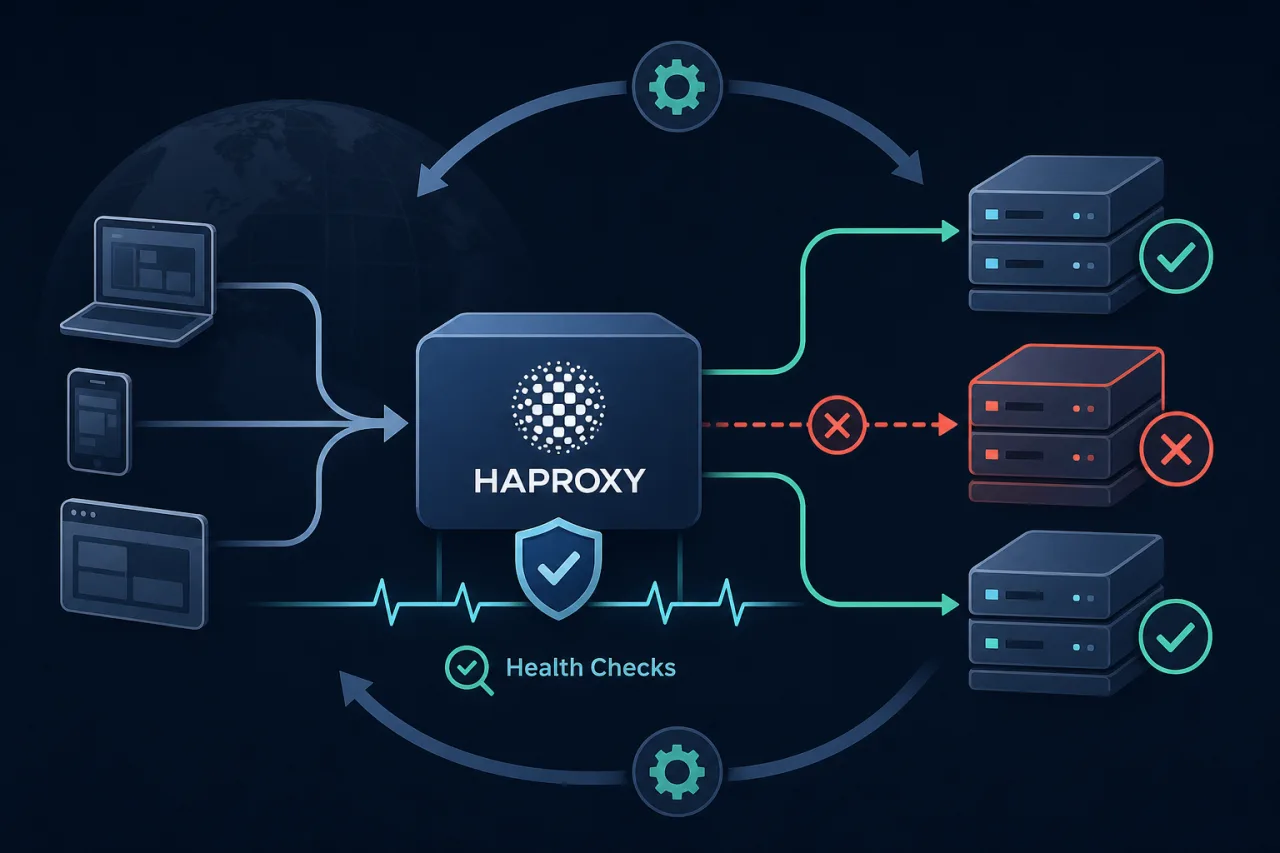
Health-Check-Based Failover with HAProxy
How to configure HAProxy's built-in health checks to automatically remove failing backends and restore them when they recover.
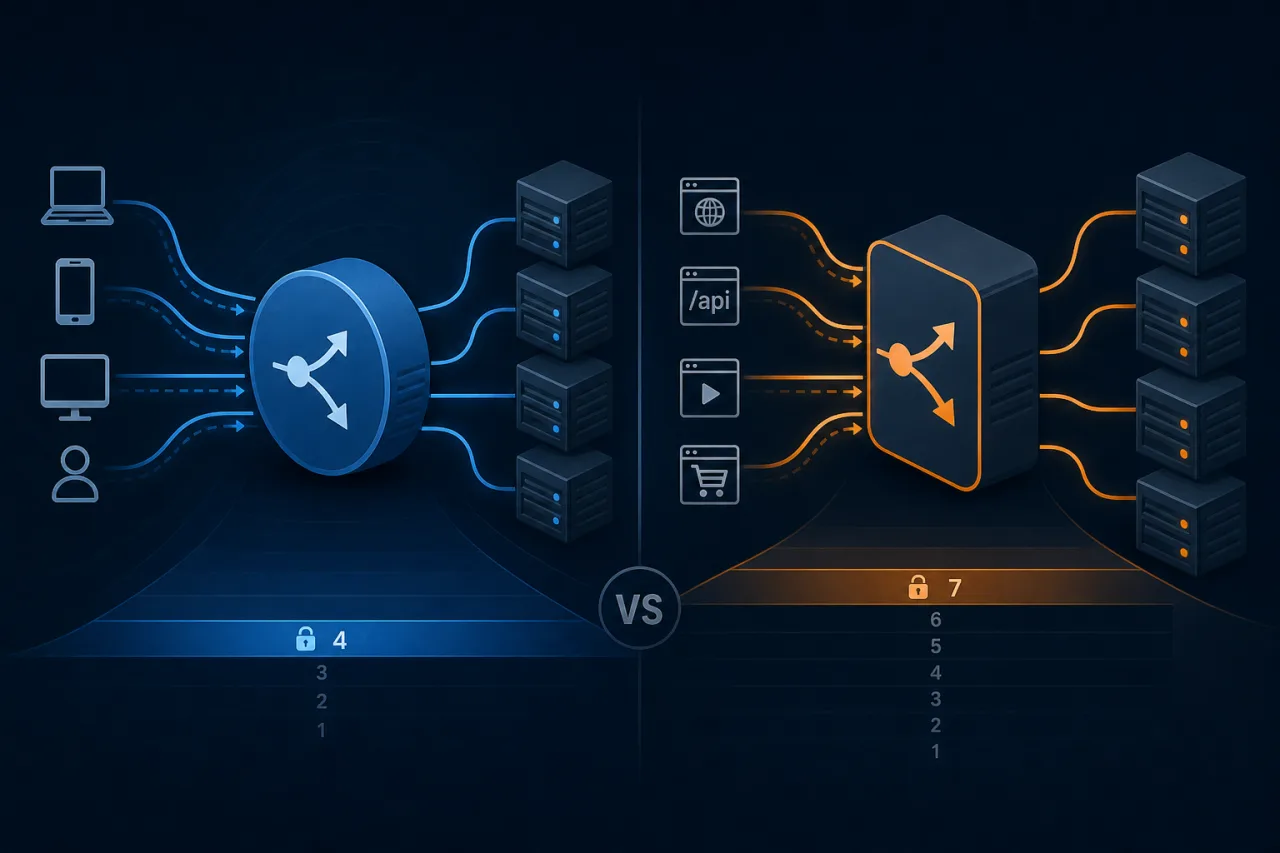
Layer 4 vs Layer 7 Load Balancing: A Practical Guide
Understand the real differences between transport-layer and application-layer load balancing so you can pick the right tool for your infrastructure.
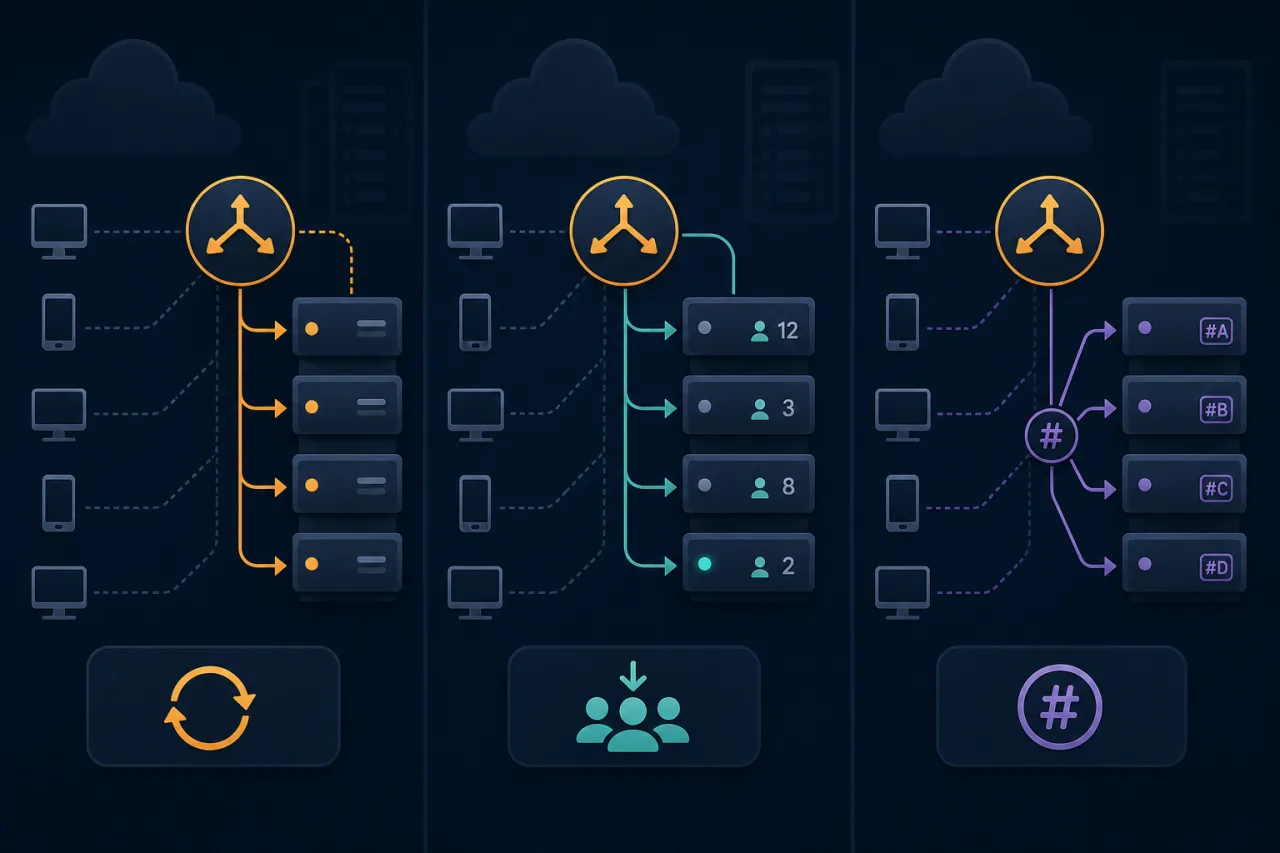
Load Balancing Algorithms Compared: Round-Robin vs Least-Connections vs Hashing
A practical breakdown of three core load balancing algorithms—when each one fits, where each one breaks, and how to choose the right one for your stack.
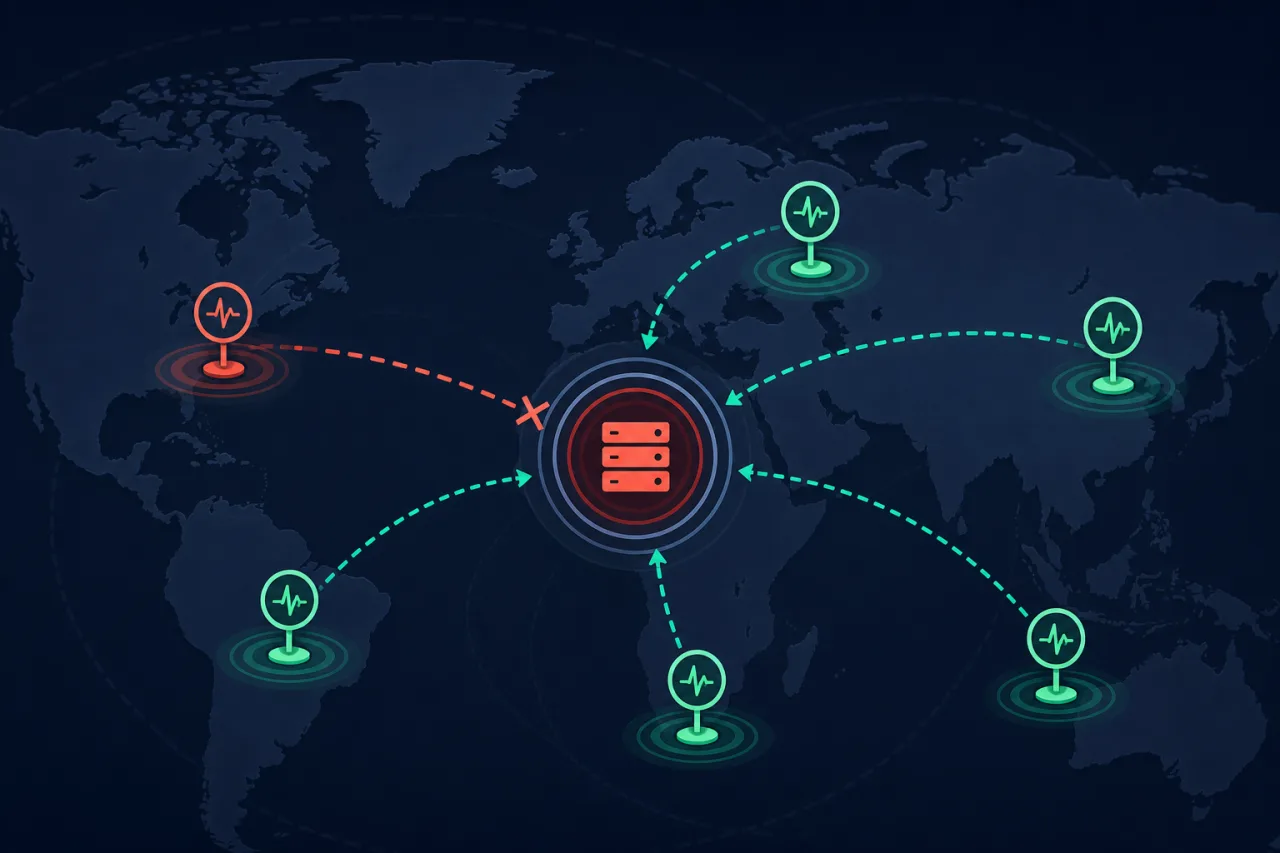
Why Multi-Region Monitoring Beats Single-Location Checks
A single monitoring probe gives you a single point of failure in your observability stack — here's why distributing checks across regions catches real outages that local monitors miss.
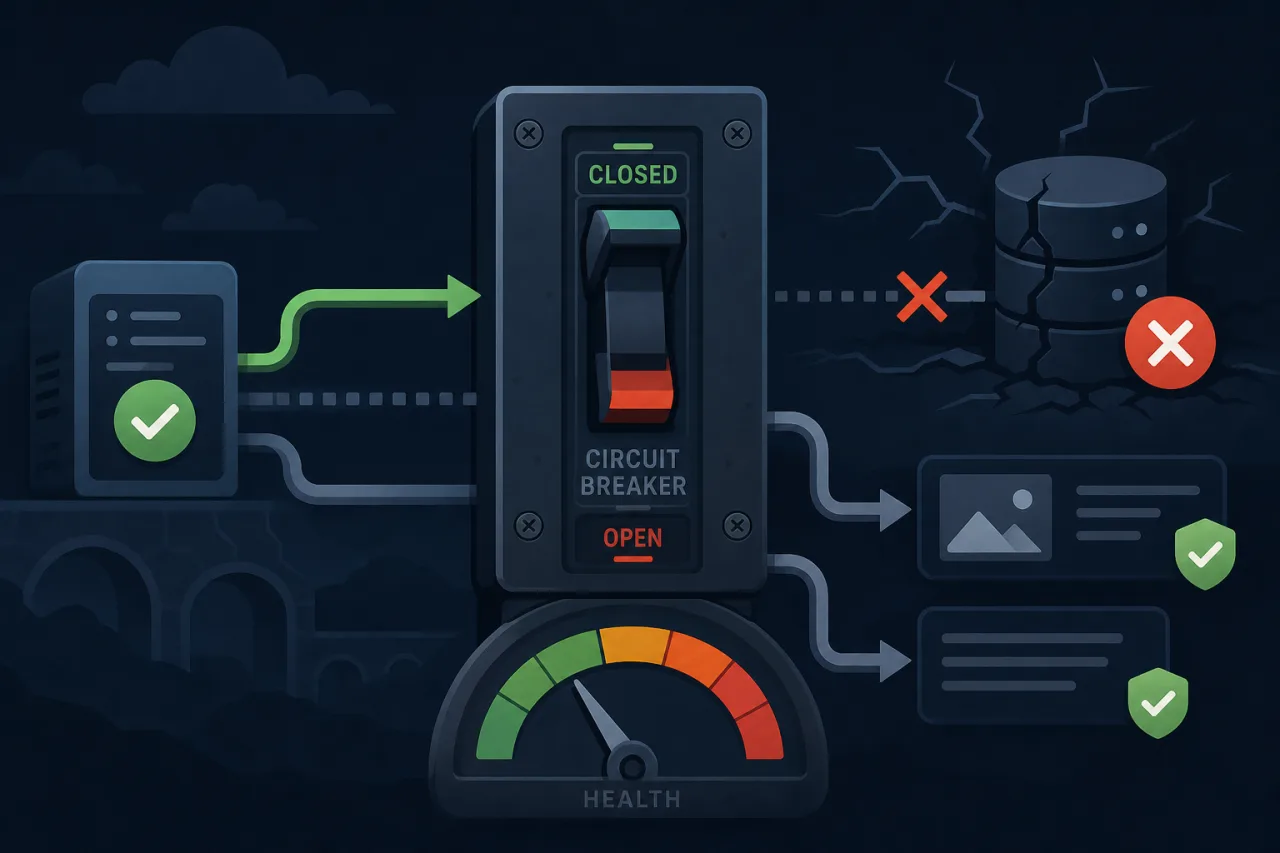
Graceful Degradation and the Circuit Breaker Pattern
How to keep your service partially alive when a dependency goes down, and how the circuit breaker pattern automates the decision to stop trying.
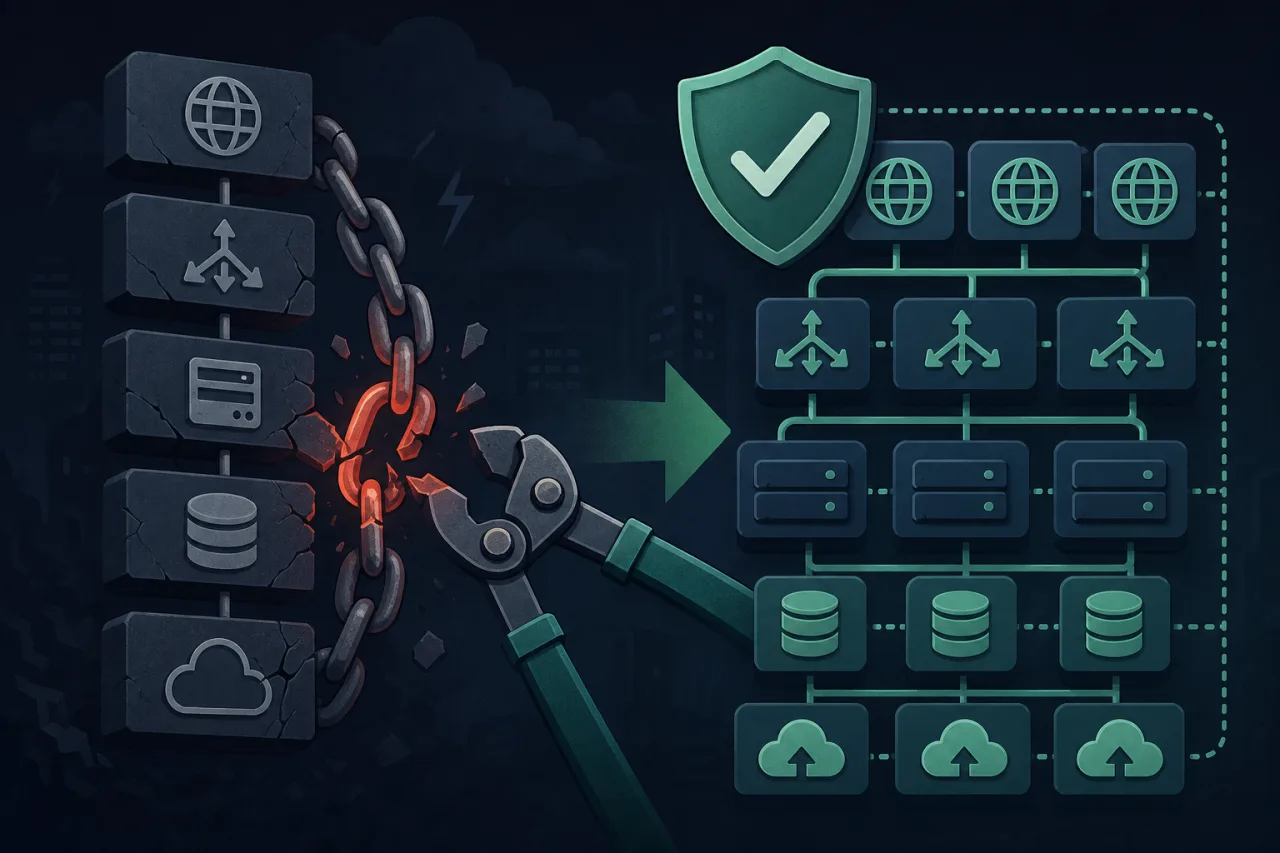
Eliminating Single Points of Failure in Your Web Stack
A practical walkthrough of where SPOFs hide in a typical web stack and how to engineer them out before they take your site down.
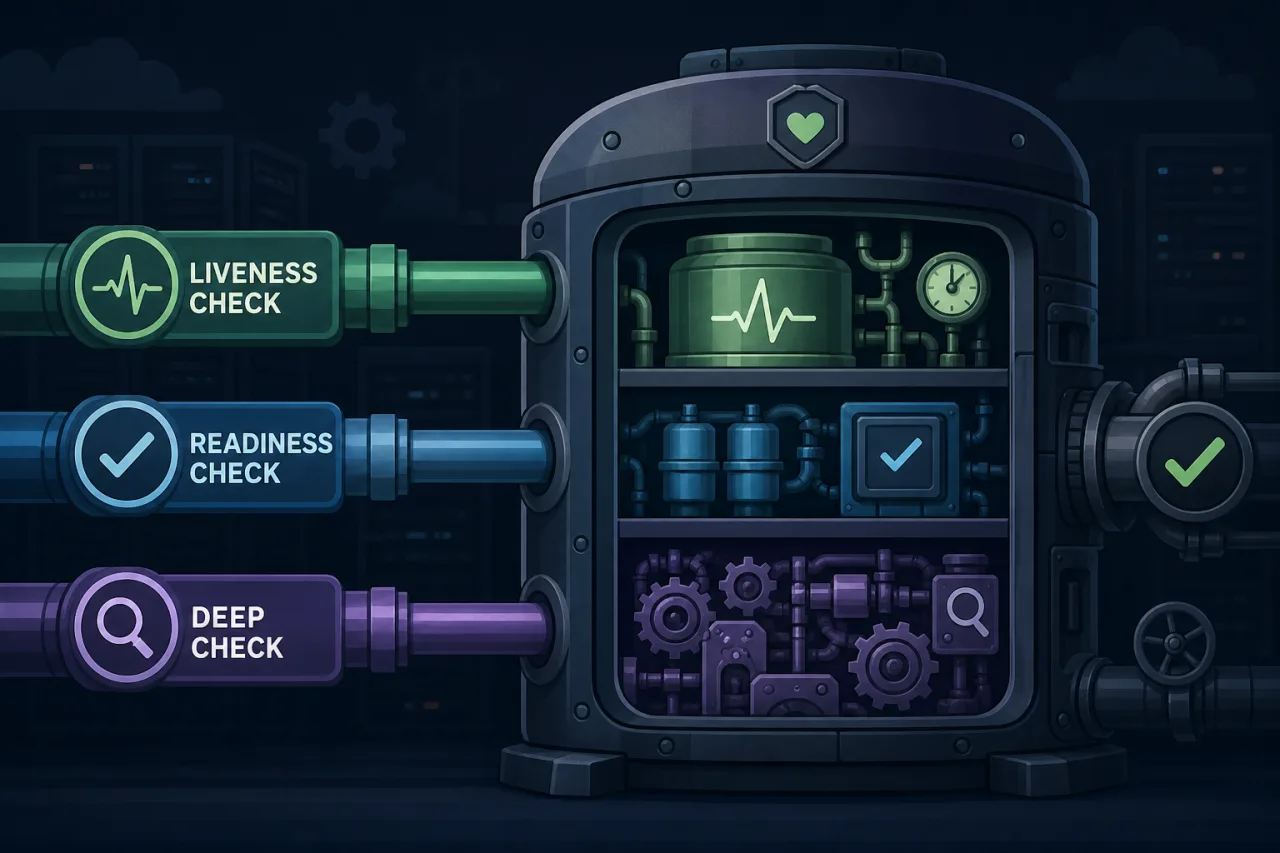
Health Checks Done Right: Liveness vs Readiness vs Deep Checks
Learn the difference between liveness, readiness, and deep health checks — and how to implement each one correctly so your monitoring actually catches real problems.

Setting Realistic SLOs, SLAs, and Error Budgets
A practical guide to defining uptime targets that your team can actually hit, measure, and defend.

How to Design for Five-Nines (99.999%) Uptime
A practical engineering guide to the architecture, tradeoffs, and operational discipline required to hit 99.999% availability.