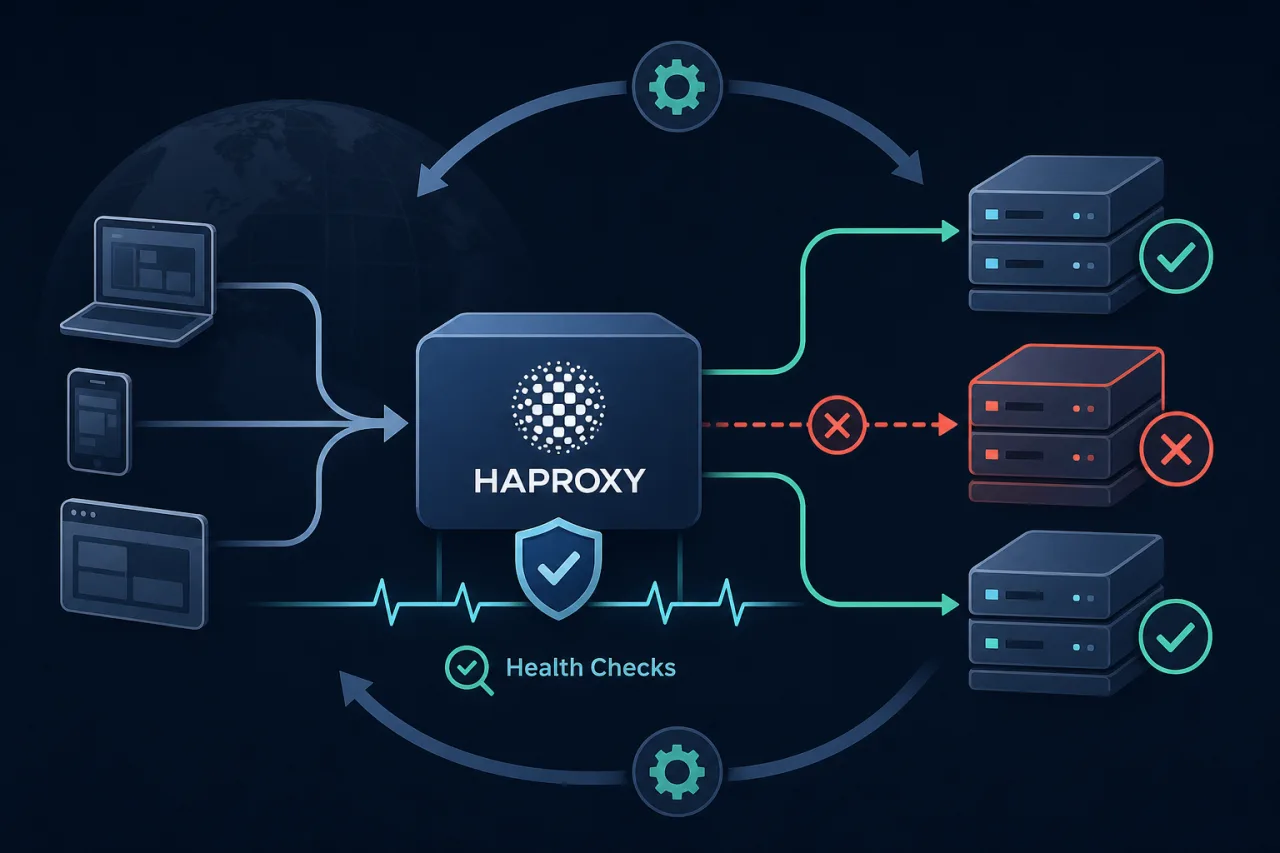
Why Passive Failover Isn't Enough
HAProxy can detect a dead backend passively — it marks a server down after a connection error. But passive detection means at least one real request hits a broken server before HAProxy reacts. Active health checks let HAProxy probe backends on its own schedule, so traffic fails over before users see errors.
This tutorial walks through a practical HAProxy configuration for HTTP health checks, tuning the thresholds, and validating that failover actually works.
Basic HAProxy Health Check Configuration
Start with a minimal haproxy.cfg backend block:
backend web_servers
balance roundrobin
option httpchk GET /healthz HTTP/1.1\r\nHost:\ api.example.com
default-server inter 3s fall 3 rise 2 timeout connect 2s timeout check 3s
server web1 10.0.0.1:8080 check
server web2 10.0.0.2:8080 check
server web3 10.0.0.3:8080 check
What Each Parameter Does
option httpchk— sends a real HTTP request instead of a TCP handshake. Use a dedicated/healthzor/healthendpoint that returns200only when the app is genuinely ready.inter 3s— probe interval. HAProxy checks each server every 3 seconds.fall 3— a server is marked DOWN after 3 consecutive failures. This prevents flapping from a single slow response.rise 2— a DOWN server is returned to rotation after 2 consecutive successes. Don't set this to 1; a server that just restarted may not be fully warm.timeout check 3s— how long HAProxy waits for the health-check response. Keep it shorter thaninter.timeout connect 2s— TCP connect timeout for the check itself.
Designing a Good /healthz Endpoint
The health endpoint is doing real work. It should:
- Return
200 OKonly when the instance can serve traffic — database connection pools open, caches warm, dependencies reachable. - Return
503 Service Unavailable(or any non-2xx) when the instance should be pulled from rotation. - Complete in well under your
timeout checkvalue — aim for under 500 ms. - Not log every hit to your main application log; use a separate access log or suppress health-check paths.
A common mistake is returning 200 from a static string while the app's database pool is exhausted. That passes the HAProxy check but fails every real request.
Handling the "Last Server Standing" Problem
If all backends fail their checks, HAProxy has nowhere to route traffic. By default it returns a 503. You have two options:
Option A — Emergency server: Designate one server as a backup that only receives traffic when all primaries are down.
server web-fallback 10.0.0.9:8080 check backup
Option B — Use option allbackups: When set, HAProxy sends traffic to all backup servers (round-robin) rather than just the first one, useful if your fallback is itself a small cluster.
In either case, the fallback should serve a maintenance page or a degraded-mode response — not silently pretend everything is fine.
Testing Failover Before You Need It
Don't wait for a real outage. Test the path:
- Enable the HAProxy stats socket:
stats socket /run/haproxy/admin.sock mode 660 - Bring a server down manually:
echo 'disable server web_servers/web1' | socat stdio /run/haproxy/admin.sock - Watch the stats page (
/haproxy-stats) or runshow servers statevia the socket to confirm the server flips to DOWN. - Verify your load balancer is still serving requests to the remaining backends.
- Re-enable:
echo 'enable server web_servers/web1' | socat stdio /run/haproxy/admin.sock - Confirm the server returns to UP after
riseconsecutive successful checks.
Running this drill periodically — especially after config changes — catches misconfigured thresholds before they matter.
Where External Monitoring Fits In
HAProxy's health checks tell you whether individual backends are healthy from the load balancer's perspective. They won't tell you if the load balancer itself is unreachable, if DNS has gone wrong, or if a whole availability zone has partitioned away from your users.
An external uptime monitor (like Pingy) probing your public endpoint from multiple regions gives you the user-facing view that HAProxy's internal checks can't provide. The two signals are complementary: internal checks drive automated failover, external checks confirm it worked and alert you when it didn't.
Key Takeaways
- Use
option httpchkwith a real application health endpoint, not a TCP check. - Tune
fallandriseconservatively — at least 2–3 for each — to avoid flapping. - Your
/healthzendpoint must reflect actual application readiness, not just process liveness. - Always configure a backup server or pool so HAProxy has somewhere to route traffic if all primaries fail.
- Test failover deliberately with the admin socket; don't assume it works because it's configured.
- Pair HAProxy's internal checks with external, multi-region monitoring to catch failures HAProxy itself can't see.