Why the Algorithm Choice Actually Matters
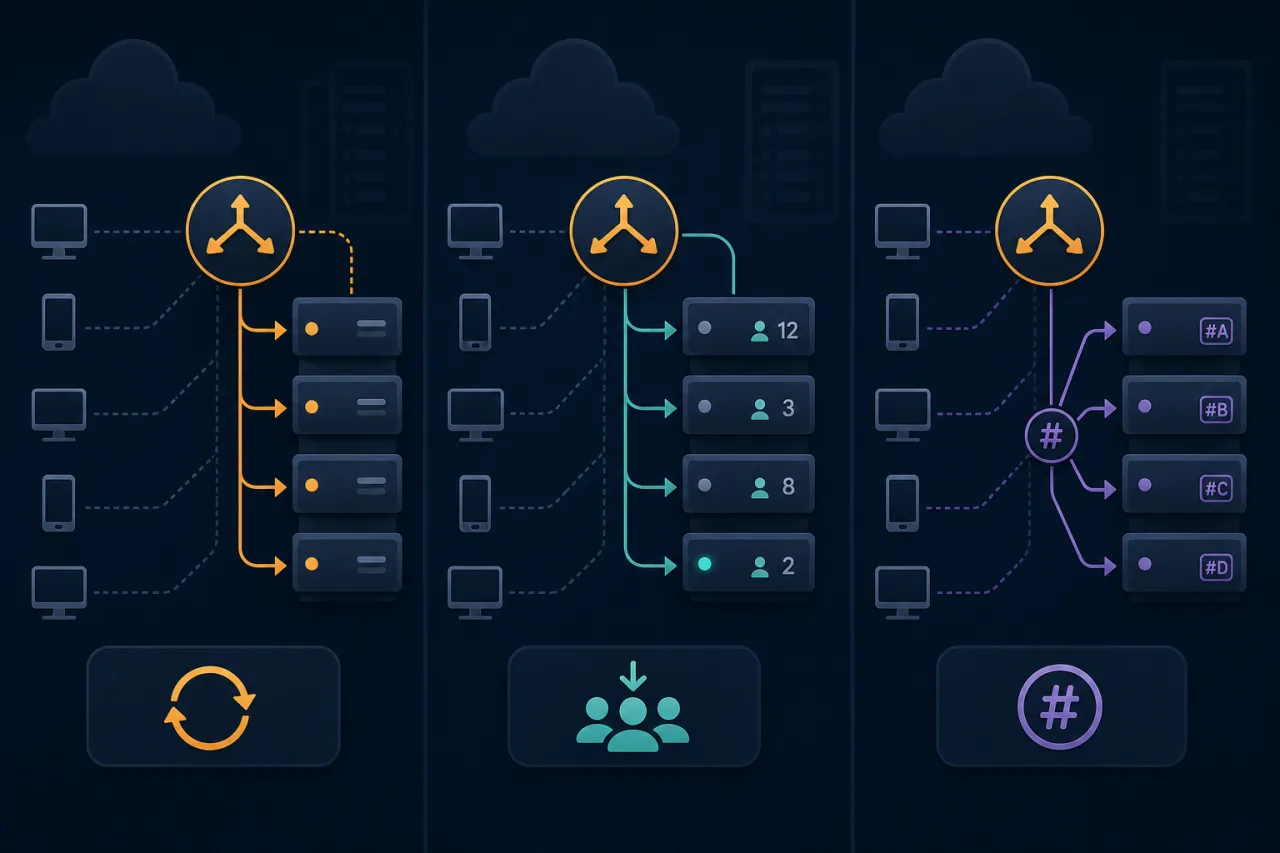
A load balancer is only as good as its scheduling logic. Pick the wrong algorithm and you get hot spots, session breakage, or uneven resource exhaustion—even when your hardware has plenty of headroom. The three algorithms you'll encounter most often are round-robin, least-connections, and hashing-based routing. They solve different problems and carry different trade-offs.
Round-Robin
Round-robin distributes requests to each backend in sequence: request 1 goes to server A, request 2 to server B, request 3 to server C, then back to A.
How it works
The load balancer keeps a pointer that advances with each new connection. Weighted round-robin extends this by giving heavier servers proportionally more turns.
When it fits
- Stateless services where any backend can handle any request
- Homogeneous server pools (same CPU, RAM, and capacity)
- Short-lived, roughly equal-cost requests (static assets, simple API calls)
Where it breaks down
Round-robin is blind to server load. If one request triggers a 10-second database query and the next is a 5ms health check, both get "one turn." Over time, slower requests accumulate on whichever backend drew the unlucky slot, creating latency spikes that are hard to diagnose.
Least-Connections
Least-connections routes each new request to whichever backend currently has the fewest active connections.
How it works
The load balancer maintains a connection count per backend, increments it when a request is assigned, and decrements it when the connection closes. The variant least-response-time also factors in measured latency, giving preference to fast and lightly loaded backends simultaneously.
When it fits
- Long-lived connections (WebSockets, streaming, large file uploads)
- Heterogeneous workloads where request cost varies significantly
- Pools where backends occasionally degrade without failing outright
Where it breaks down
Least-connections adds bookkeeping overhead and can make suboptimal decisions when connections close in bursts. In high-throughput, short-lived HTTP/1.1 scenarios the connection count can be near-zero on all backends simultaneously, which degrades to round-robin behavior anyway. It also does nothing for sticky sessions.
Hashing-Based Routing
Hashing routes requests to a backend determined by a hash of some request attribute—typically the client IP, a session token, or a URL path.
How it works
The load balancer computes hash(key) mod N (where N is the backend count) and sends the request to the resulting server. Consistent hashing uses a hash ring so that adding or removing a backend only remaps a fraction of keys, rather than scrambling the entire distribution.
When it fits
- Stateful applications that can't share session data between backends
- Cache-heavy services where you want the same backend to hold warm cache entries for a given user or resource
- Microservice fan-out where you need predictable request routing for debugging
Where it breaks down
If your key space isn't well distributed—say, many users share a corporate NAT and map to the same IP—you'll hammer one backend. Consistent hashing mitigates rebalancing churn but doesn't solve skew from a bad key choice. Also, a backend failure voids sticky guarantees for the affected key range.
Choosing the Right Algorithm: A Decision Checklist
Work through these questions in order:
- Are your requests stateless and uniform? Start with round-robin. Add weights if backends differ in capacity.
- Do request durations vary widely or are connections long-lived? Switch to least-connections or least-response-time.
- Does the application require session affinity or warm caches? Use consistent hashing with a stable, high-cardinality key (session ID is better than IP).
- Are you scaling horizontally and need minimal rebalancing on backend changes? Consistent hashing is mandatory; plain modulo hashing will thrash.
- Do you have mixed workloads? Some proxies (Nginx, HAProxy, Envoy) let you combine approaches per listener or upstream group—use that.
Observability Ties It Together
No algorithm choice survives contact with production without monitoring. Backend response time distributions, connection queue depth, and error rates per upstream all tell you whether your chosen algorithm is actually working.
Multi-region uptime monitoring—checking your endpoints from multiple geographic vantage points—helps surface regional imbalances that internal metrics miss. If your European nodes are responding in 800ms while US nodes sit at 80ms, your load balancer metrics won't flag it, but external synthetic checks will.
Key Takeaways
- Round-robin is the right default for stateless, homogeneous workloads; add weights for capacity differences.
- Least-connections pays off when request cost varies or connections are long-lived; consider least-response-time for extra precision.
- Hashing is the only correct choice when you need affinity or cache locality; prefer consistent hashing over modulo to handle fleet changes gracefully.
- A bad key for hashing causes hot spots that look identical to backend failures—monitor per-backend traffic distribution, not just aggregate throughput.
- Algorithm selection and observability are inseparable; instrument your upstreams before you tune your scheduler.